2021. 6. 10. 11:22ㆍ딥러닝
arxiv, github, twitter(저자 아님), Microsoft
참고 : 다음에 나온 Scaled-YOLOv4가 이 논문 이김.
요약
vision이 language와 차이점
1) large variation 2) high resolution
shifted windows를 도입한 계층적 transformer를 제안함.
shifted windows는 non-overlapping한 windows를 연결함.
장점 : 1) various scale에 가능 2) O(n), n : image size

Introduction
앞선 sliding windows방식의 self-attention은 low latency임.
우리 논문에서는 all query patch가 같은 key를 공유함. -> latency 해결.

Related work
Transformer based vision backbones
ViT는 non-overlapping medium-sized image patches로 구성됨.(오직 classification을 위해서)
그리고 데이터셋이 커야함.
DeiT는 작은 데이터셋에서도 ViT를 학습 가능하게 만듦.(ImageNet-1K)
그러나 ViT모델은 Dense Vision Task(=detection+segmentation)에는 적합하지 않음
이유 : 1) low-resolution feature mapping 2) O(image_size^2)
Swin Transformer : speed-accuracy trade-off
[Pyramid vision transformer: A versatile backbone for dense prediction without convolutions.]에서 multi-resolution방법 사용했지만 O(image_size^2).
Method
patch size = $4 \times 4 \times 3=48$($3$은 RGB)

$1$ windows = $M \times M$ patches.
Non-overlap

Shifted window partitioning

shifted window partitioning
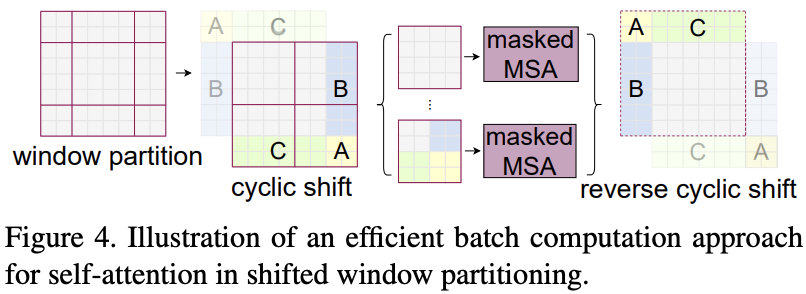
cyclic-shift가 batched windows의 수를 일반 window partitioning과 같게 유지함. 매우 효율적.(low latency)
Relative position bias

position embedding을 input에 넣었더니 성능 떨어짐. 그래서 뺐음.
의문점 : $B$ 는 훈련이 되는건가?
Architecture Variants

Experiments

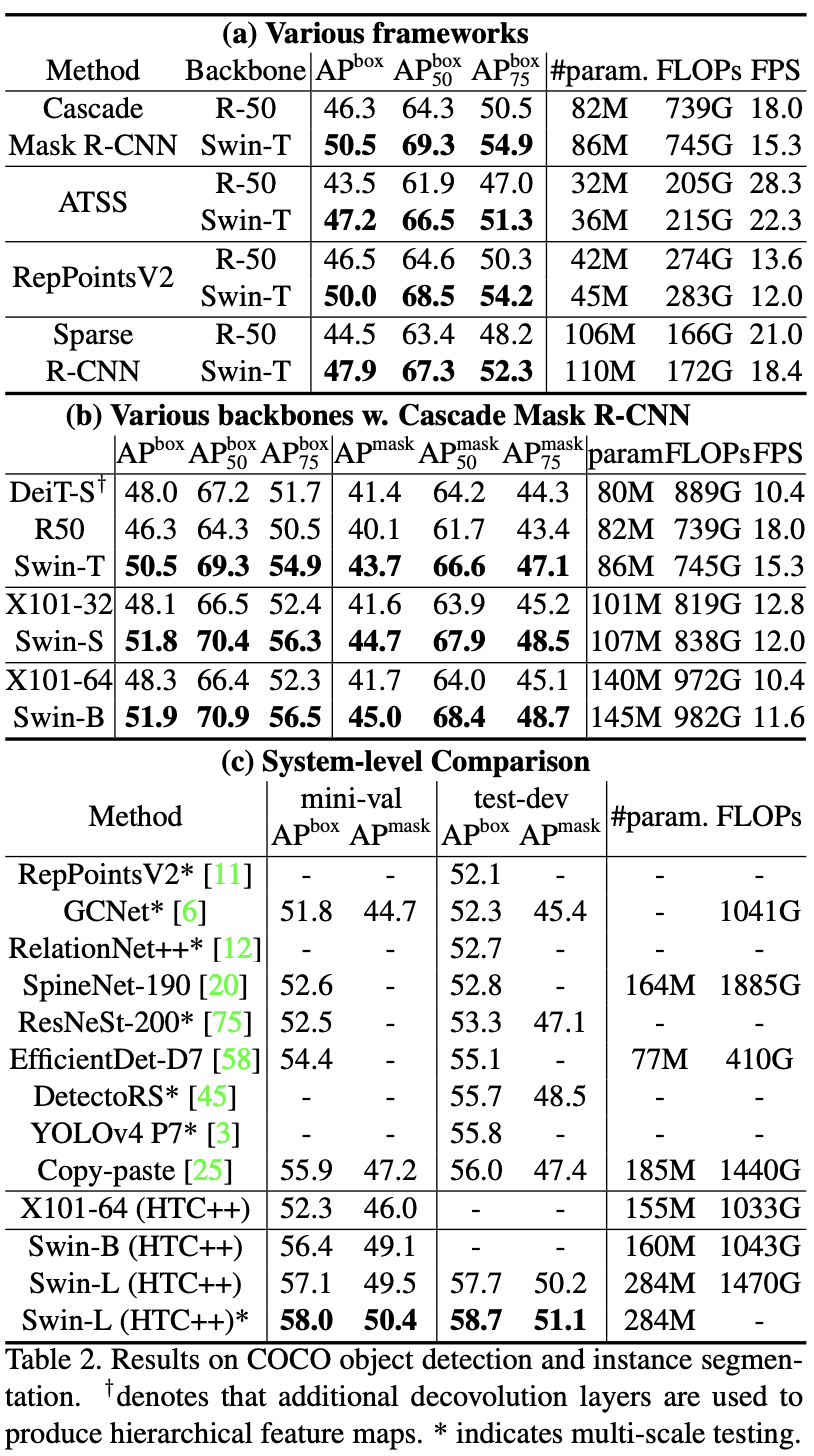
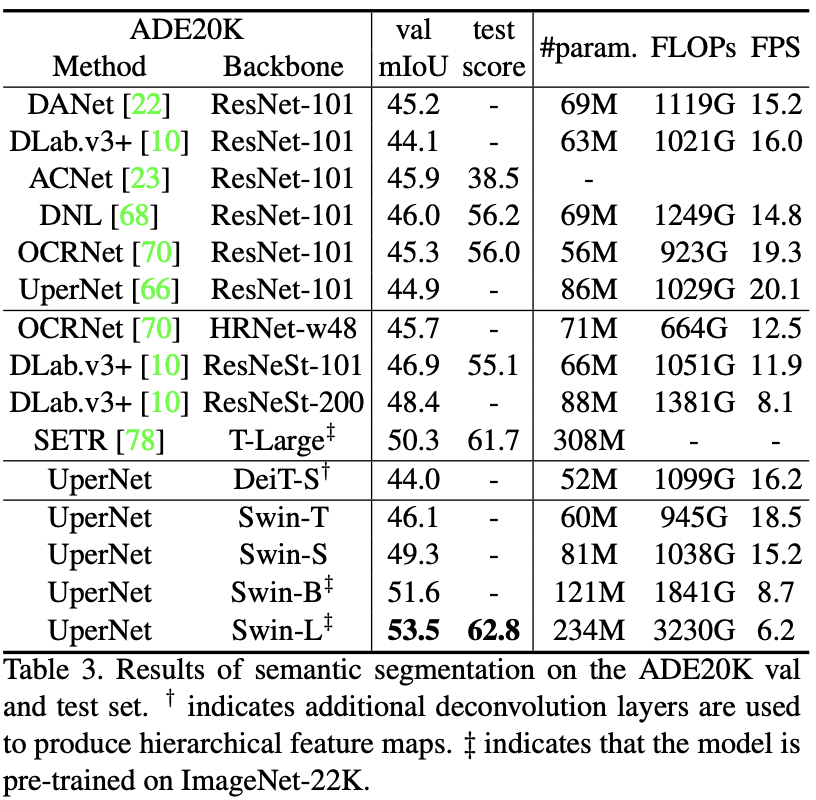
Abaliation study


'딥러닝' 카테고리의 다른 글
| [Review] Perceptual Losses for Real-Time Style Transfer and Super-Resolution (0) | 2021.06.15 |
|---|---|
| Intriguing Properties of Vision Transformers (0) | 2021.06.10 |
| Automatic Mixed Precision 적용하기 (0) | 2021.05.10 |
| DatasetGAN: Efficient Labeled Data Factory with Minimal Human Effort (0) | 2021.04.30 |
| AI Song Contest: Human-AI Co-Creation in Songwriting (0) | 2021.04.26 |
