Automatic Mixed Precision 적용하기
2021. 5. 10. 18:34ㆍ딥러닝

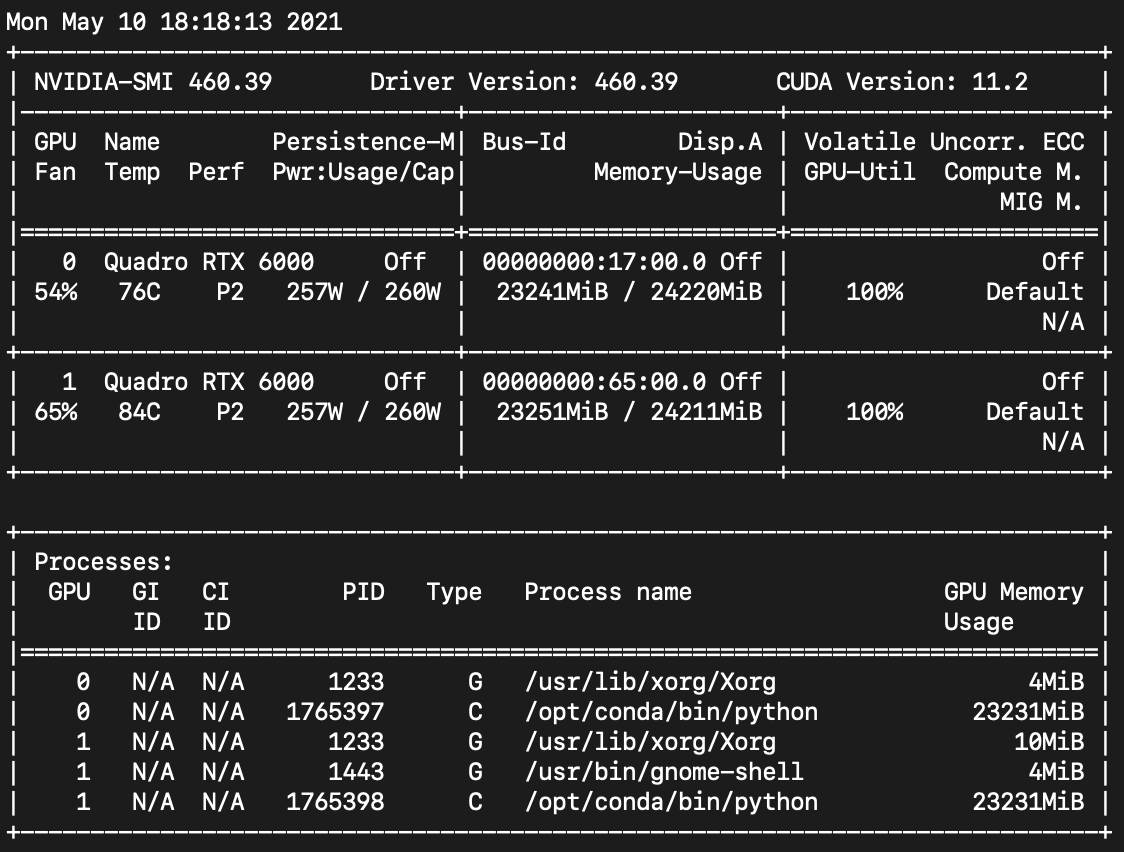
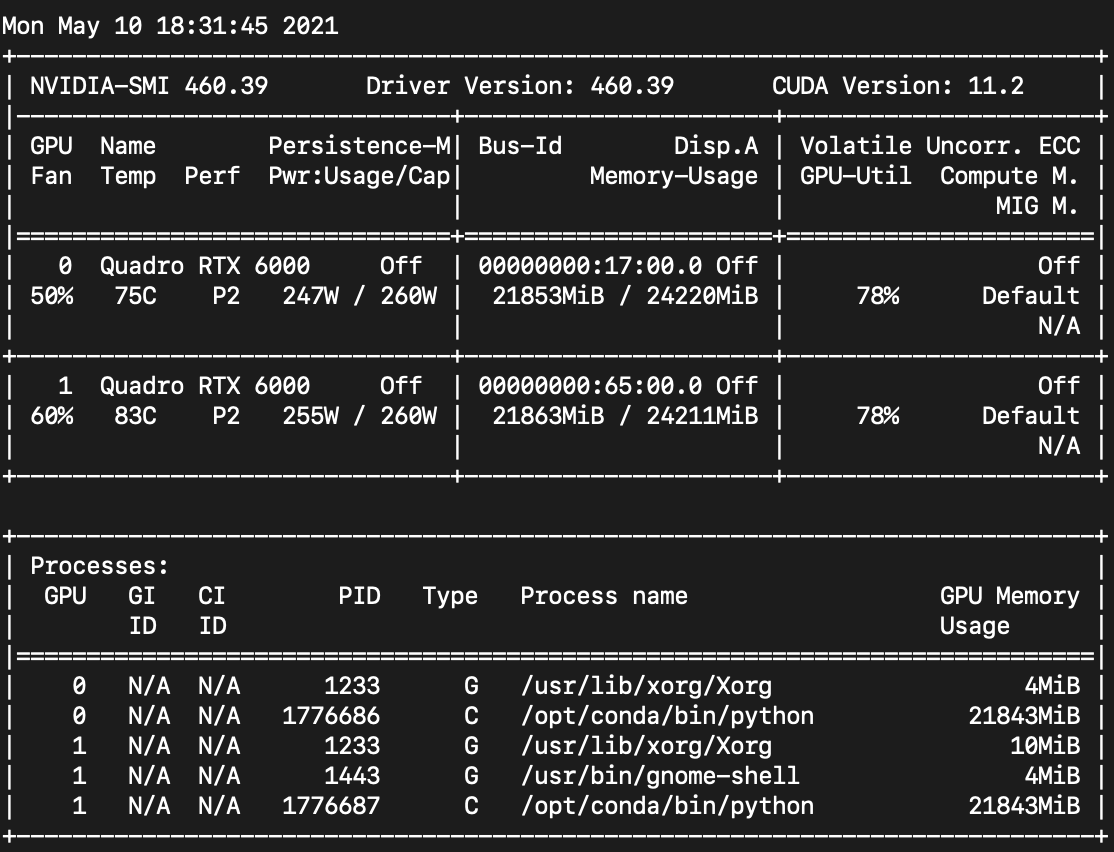

amp_examples.html#distributeddataparallel-one-gpu-per-process에 의하면 DDP가 스레드를 의도적으로 spawn하지 않는다고 한다. 따라서 autocast와 GradScaler가 영향받지 않는다.
따라서 사용못한다,(?)
'딥러닝' 카테고리의 다른 글
| Intriguing Properties of Vision Transformers (0) | 2021.06.10 |
|---|---|
| Swin Transformer: Hierarchical Vision Transformer using Shifted Windows (0) | 2021.06.10 |
| DatasetGAN: Efficient Labeled Data Factory with Minimal Human Effort (0) | 2021.04.30 |
| AI Song Contest: Human-AI Co-Creation in Songwriting (0) | 2021.04.26 |
| Aleatoric and Epistemic Uncertainty - Alex Kendall (0) | 2021.03.31 |
